第 1 集 前置知识点回顾和热门中间件知识点速览
简介: 前置知识点回顾和热门中间件知识点速览
-
串讲数据结构板块
-
热门中间件知识点速览
- 面试题
- MySQL 索引为什么使用 B+ 树而不使用跳表?
- 说说主流中间件选择 LSM tree 与 B-Tree/B+Tree 会基于怎样的思考?
- Mysql 的 InnoDB 引擎 3 层的 B+树可以存储多少条数据 ?
- MySQL 的索引为什么使用 B+ 树而不使用跳表?
第 2 集 高性能 IO 数据结构之跳表 SkipList 原理
简介: 高性能 IO 数据结构之跳表 SkipList 原理
-
背景
- 链表中存储的有序数据,要查找某个数据,只能从头到尾遍历链表,查找效率就会很低,n 个元素 时间复杂度会很高 O(n)

-
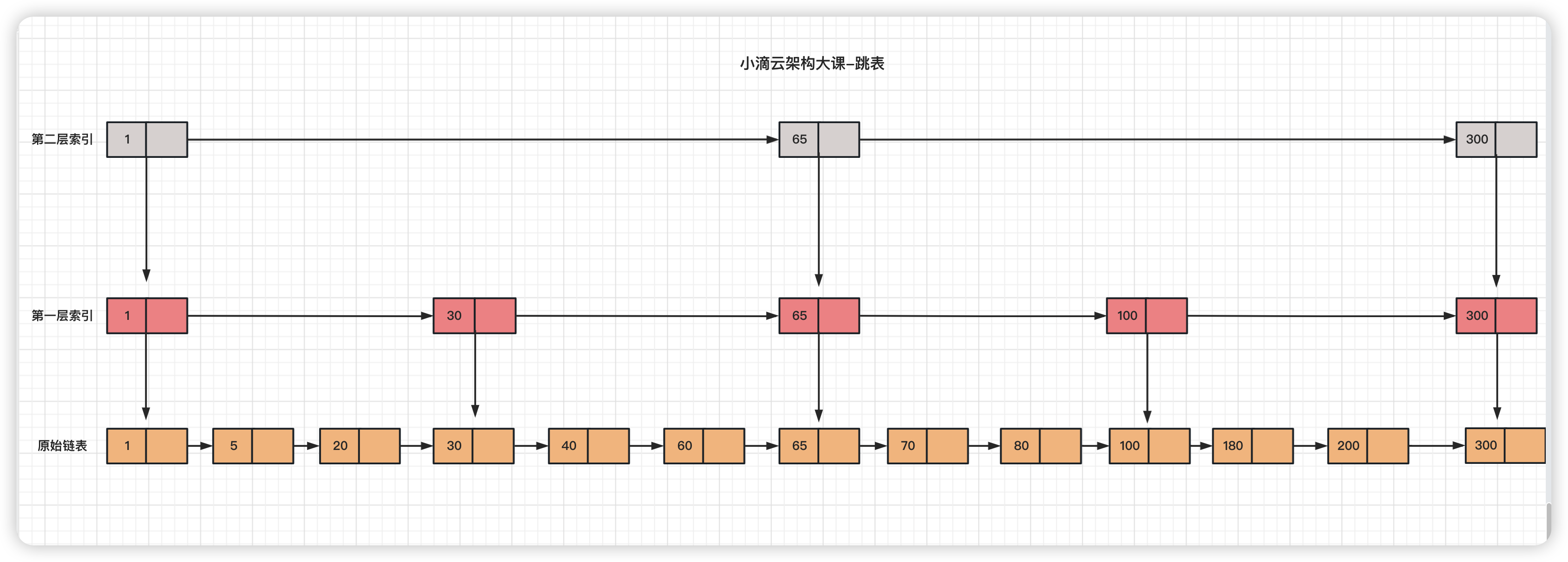
什么是跳跃表(skip list)
- 是一种基于跳跃链表的有序数据结构,它是一种多层链表,每一层都是一个有序的链表
- 跳跃表的每一层都有一个指向下一层的指针,可以快速跳转到更深层次的链表,支持快速的插入、搜索和删除操作
- 原理
- 它会把数据按照一定的规则分成多个层次,每一层都是有序的,并且每一层的元素数量都比下一层少一半
- 在搜索从最高层开始,比较要查找的元素和当前层的元素,如果要查找的元素比当前层的元素小,则可以跳转到下一层
- 如果要查找的元素比当前层的元素大,则继续比较下一个元素,直到找到要查找的元素为止。
- 优点
- 搜索时间复杂度可以达到 O(logN),比传统的二分搜索树要快得多,且它的内存占用也比较少,节省大量的内存空间。
- 缺点
- 需要额外的存储空间来存储每一层的指针,而且它的插入和删除操作比较复杂,需要更新多个指针。
- 比起单链表,跳表需要存储多级索引,要消耗更多的存储空间,空间换时间的思路
- 流程
- 对链表建立一级“索引”,查找起来会更快,每隔几个结点提取一个结点到上一级,把抽出来的那一级叫做索引层
- 每加来一层索引之后,查找一个结点需要遍历的结点个数减少,时间复杂度也下降
- 比如要查找 60,从第一层索引查找到第 3 个节点发现 65 比 60 大,则回到 30 所在节点下降到一层,继续往前查找即可找到
- 应用场景
- Redis 的 Sorted Set 使用跳表来实现
- Redis 的每种数据结构操作,实际上都是基于多种底层数据结构实现
第 3 集 面试题-MySQL 索引为什么使用 B+ 树而不使用跳表
简介: 面试题-MySQL 的索引为什么使用 B+ 树而不使用跳表
-
面试题:
-
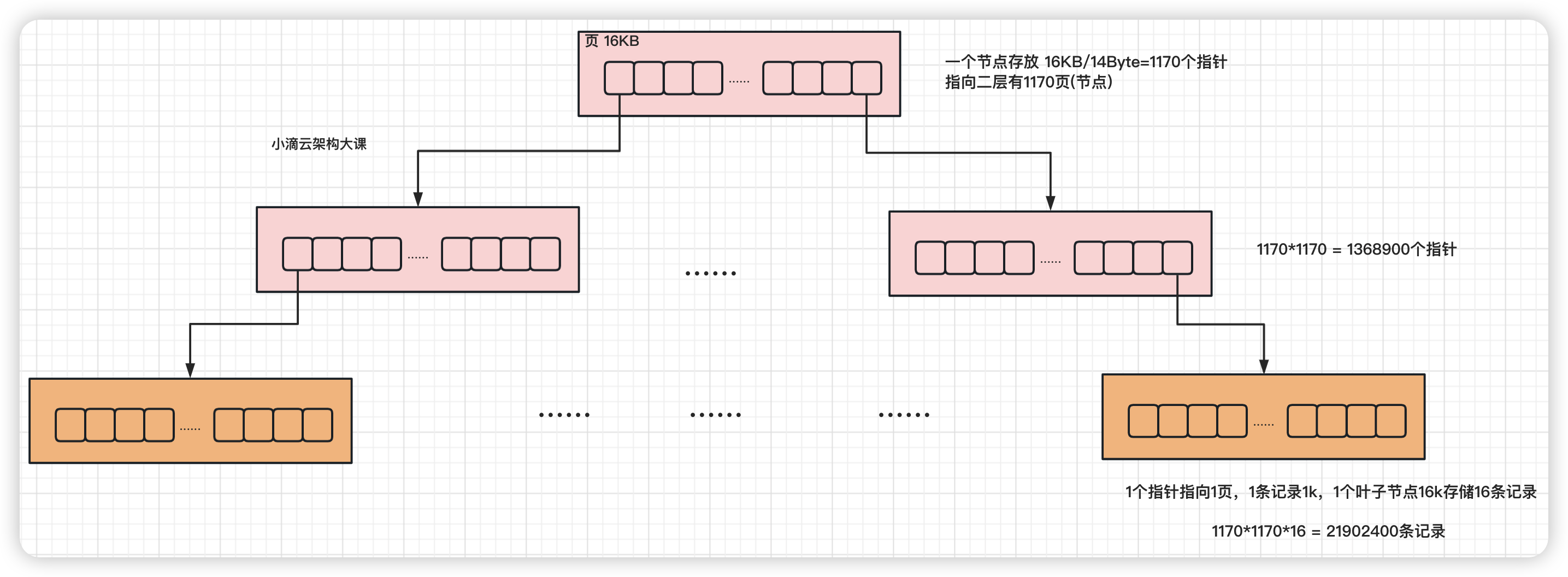
Mysql 的 InnoDB 引擎 3 层的 B+树可以存储多少条数据 ?
-
MySQL 的索引为什么使用 B+ 树而不使用跳表?
-
答案
-
跳表是链表结构,一个节点存储一个数据,如果最底层要存放 2kw 的数据,达到二分查找的效果
- 跳表的大概高度在 24 层左右(2kw 大概是 2 的 24 次方)
- 如果数据分布不好的情况下, 24 层数据会分散在不同的数据页里,查一次数据会经过 24 次磁盘 I/O
- 存放同样量级的数据,B+ 树的高度比跳表要小,MySQL 查询多,磁盘 I/O 次数更少,因此 B+ 树查询更快
- Redis 使用跳表而不使用 B+ 树
- 进行读写数据时都是内存操作,数据量相对少,不操作磁盘,因此也不存在磁盘 I/O,所以层高就不再是跳表的缺点
- 写操作 B+树要进行拆分索引数据页,跳表是独立插入,没有旋转和维持平衡的开销,跳表的写入性能会比 B+ 树更好
第 4 集 高性能 IO 数据结构之 LSM 树原理
简介:高性能 IO 数据结构之 LSM 树原理
第 5 集 面试题-数据存储 LSM tree 与 BTree 选择的思考
简介:面试题-数据存储 LSM tree 与 BTree 会基于怎样的思考
-
LSM 树的设计思想总结
-
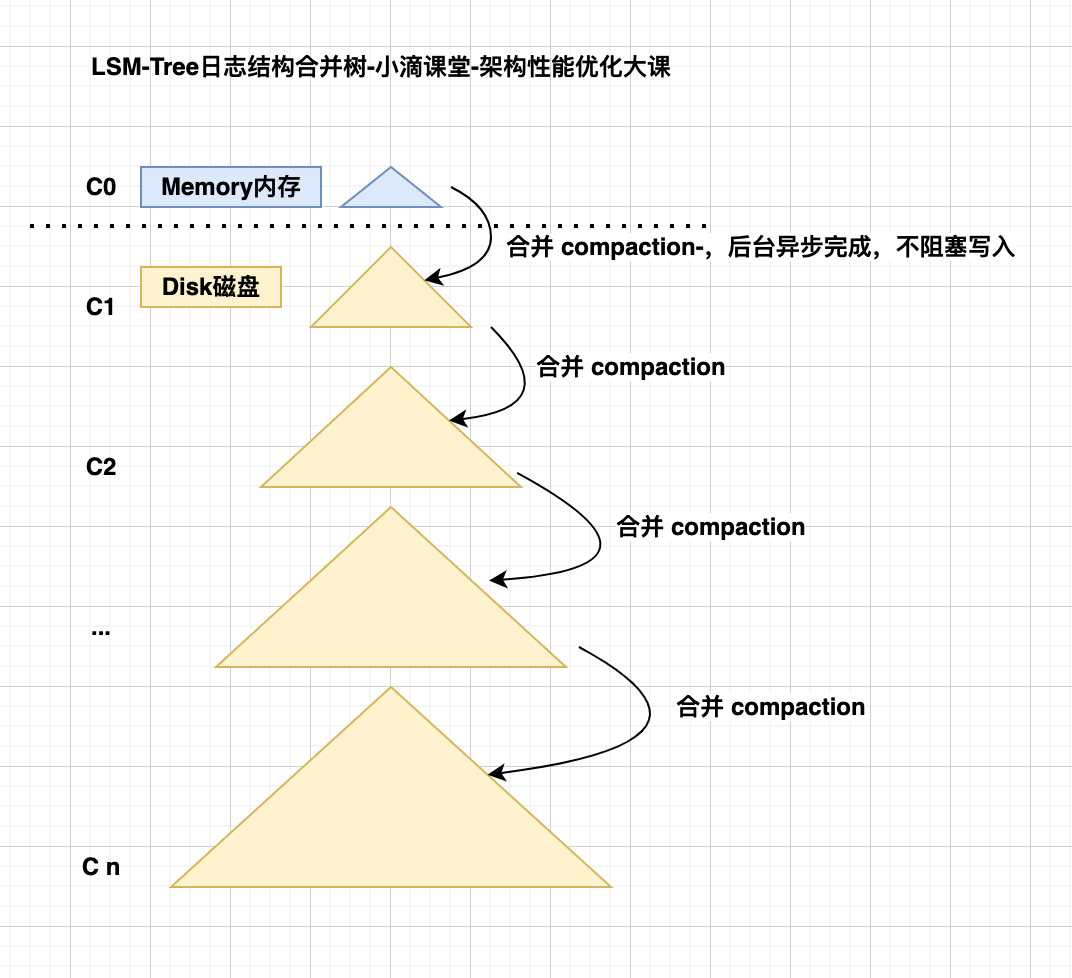
充分利用了磁盘顺序写的特性,实现高吞吐写能力,数据写入后定期在后台 Compaction
-
在数据导入时全部是顺序 append 写,在后台合并时也是多个段 merge sort 后顺序写回磁盘
-
针对写快读慢特点,比较适合那些 数据插入操作远多于数据更新/删除/读操作的场景
-
但是肯定有很多同学疑惑,读能力应该是大部分存储系统最应该保证的能力,所以用读换写似乎不是个好方案
-
为了提高读取性能,LSM Tree 采用了多种优化方案
- Bloom filter
- 是一种带随机概率的 bitmap,可以快速的判断某一个小树里有没有指定的那个数据
- 避免了更多的 IO 查找,只需经过几个哈希函数计算就能知道数据是否在某个小树里
- 查询效率得到了提升,但需要付出额外的存储空间,和维护布隆过滤器
- compact
- 查询的时候去读取多个小树会有性能问题,通过后台进程不断地将小树合并到大树上
- 程序查询的时候就可以直接读取大树,从而提高读取性能
-
写入流程
- 关键点
- 先将数据的操作存到内存中,由 log 记录,同时触发相关的更新,例如布隆过滤器,方便后续查询
- 当内存的 MemTable 达到阈值时通过归并排序方式合并放到磁盘队尾
- 防止内存因断电等原因丢失数据,写入内存的数据同时会顺序在磁盘上预写日志(WAL), LSM 这个词中 Log 一词的来历
- put 操作,首先追加到写前日志(Write Ahead Log)并更新其结构,然后加到 C0 层
- 当 C0 层的数据达到一定大小,就把 C0 层 和 C1 层合并,这个过程就是 Compaction(合并)
- 合并出来的新的 C1 会顺序写磁盘,替换掉原来的 C1
- 当 C1 层达到一定大小,会和下层继续合并,合并后删除旧的,留下新的
- 查询流程
- 关键点
- LSM Tree 提升读性能的优化策略主要是使用布隆过滤器、多路归并机制
- 进行查询时 先检查布隆过滤器,如果布隆过滤器报告数据不存在,则直接返回不存在
- 在查询时,先使用二分搜索检索对应的稀疏索引/平衡二叉树,找到数据所在的范围,再读取磁盘上该范围内的数据
- 最新的数据在 C0 层,最老的数据在 Cn 层
- 查询也是先查 C0 层,如果没有要查的数据,再查 C1,逐层查下去直到最后一层
- 面试题:说说主流中间件选择 LSM tree 与 B-Tree/B+Tree 会基于怎样的思考
- B-Tree/B+Tree
- 关系型数据库均以 B-Tree/B+Tree 作为其构建索引的数据结构,大量数据下 B/B+ tree 提供了比较高的查询效率
- 但 B-Tree/B+Tree 的相应缺点插入或删除一条数据时,均需要更新索引,需要一次随机磁盘 IO
- 所以 B+tree 只适用于频繁读、较少写的场景,如果在多写少读的场景下,将造成大量的随机磁盘 IO,导致性能骤降
- LSM tree
- 充分利用了磁盘顺序写的特性,实现高吞吐写能力,数据写入后定期在后台 Compaction
- 在数据导入时全部是顺序 append 写,在后台合并时也是多个段 merge sort 后顺序写回磁盘
- 避免了高并发写场景下的磁盘 IO 开销,查询效率无法达到 O(logn),但依然非常快
- 本质上来说,LSM tree 牺牲了一部分查询性能,换取较高的写入性能, 在 key-value 型或日志型数据库是非常重要的
- 缺点
- 读放大
- 读取数据时实际读取的数据量大于真正的数据量,在 LSM 树中需要先在 C0 查看当前 key 是否存在,不存在继续从 Cn 层中寻找
- 写放大
- 写入数据时实际写入的数据量大于真正的数据量,在 LSM 树中写入时可能触发 Compact 操作,导致实际写入的数据量远大于该 key 的数据量

