第 1 集 哈希表原理和冲突碰撞解决方案
简介: 哈希表原理和冲突碰撞解决方案
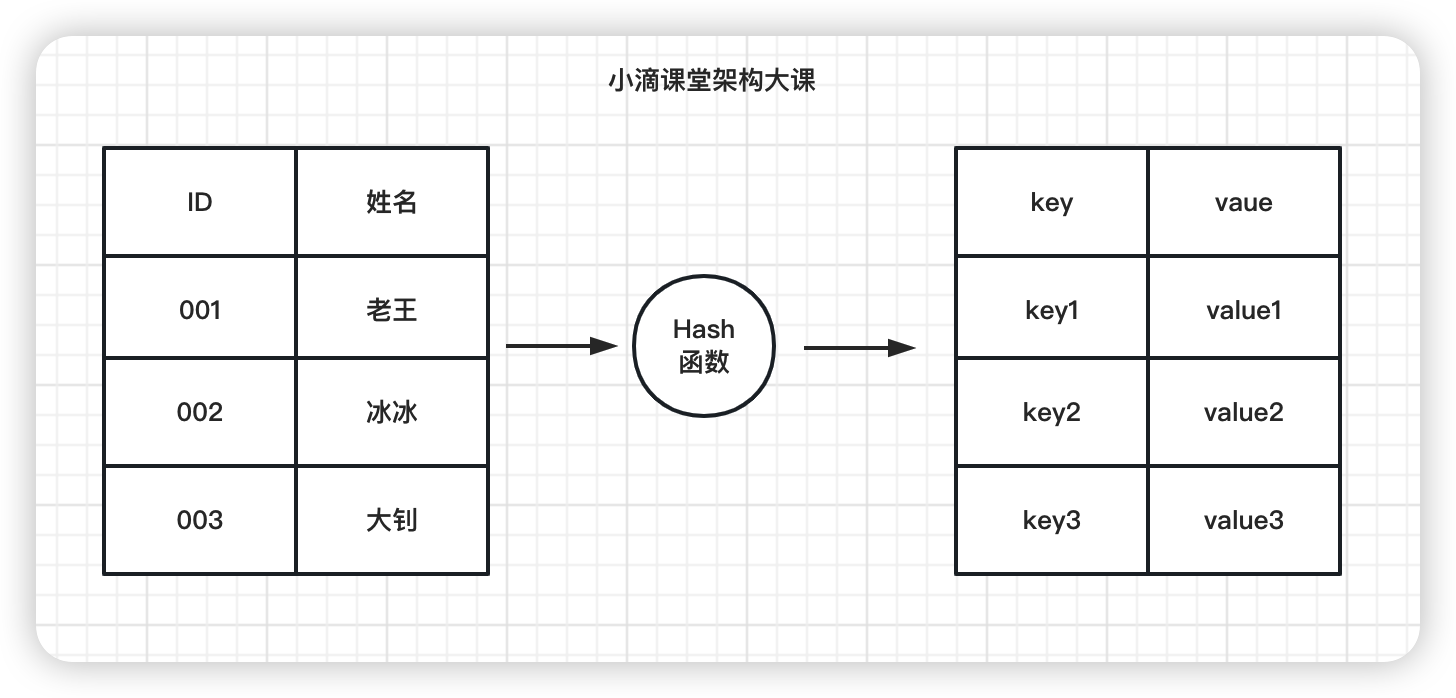
-
关键问题:hash 冲突碰撞
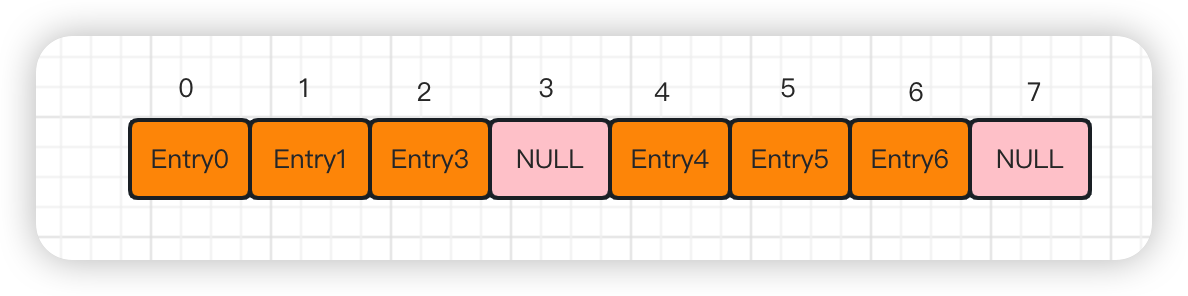
-
常见的冲突解决办法
-
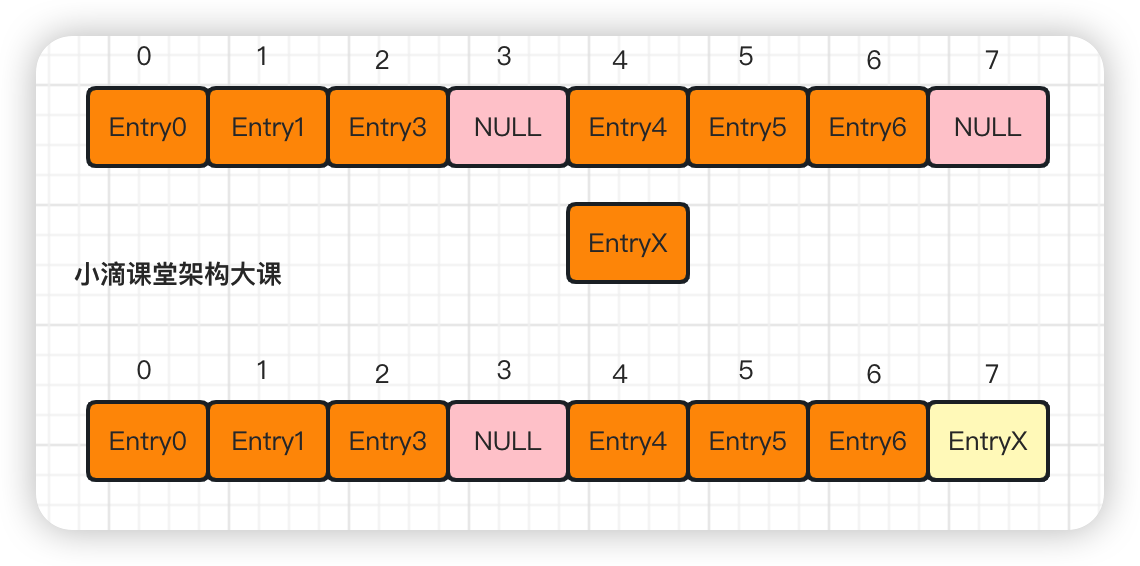
开放地址法
- 存操作
- 当某个 Key 通过哈希函数获得对应的 bucket 下标被占用时,继续寻找后续未被占用的 bucket 存储
- 也就是改变冲突位置,将元素放到下一个空闲位置中
- 读操作
- 把 Key 通过哈希函数转化成数组下标,即 bucket 桶的位置
- 找到 bucket 下标所对应的 Entry,判断 key 是否正确,正确则直接获取对应的 value
- 如果不正确,说明产生 hash 冲突, 则顺着 bucket 节点继续往下遍历,直到找到 key 一样的 entry,即可取值
-
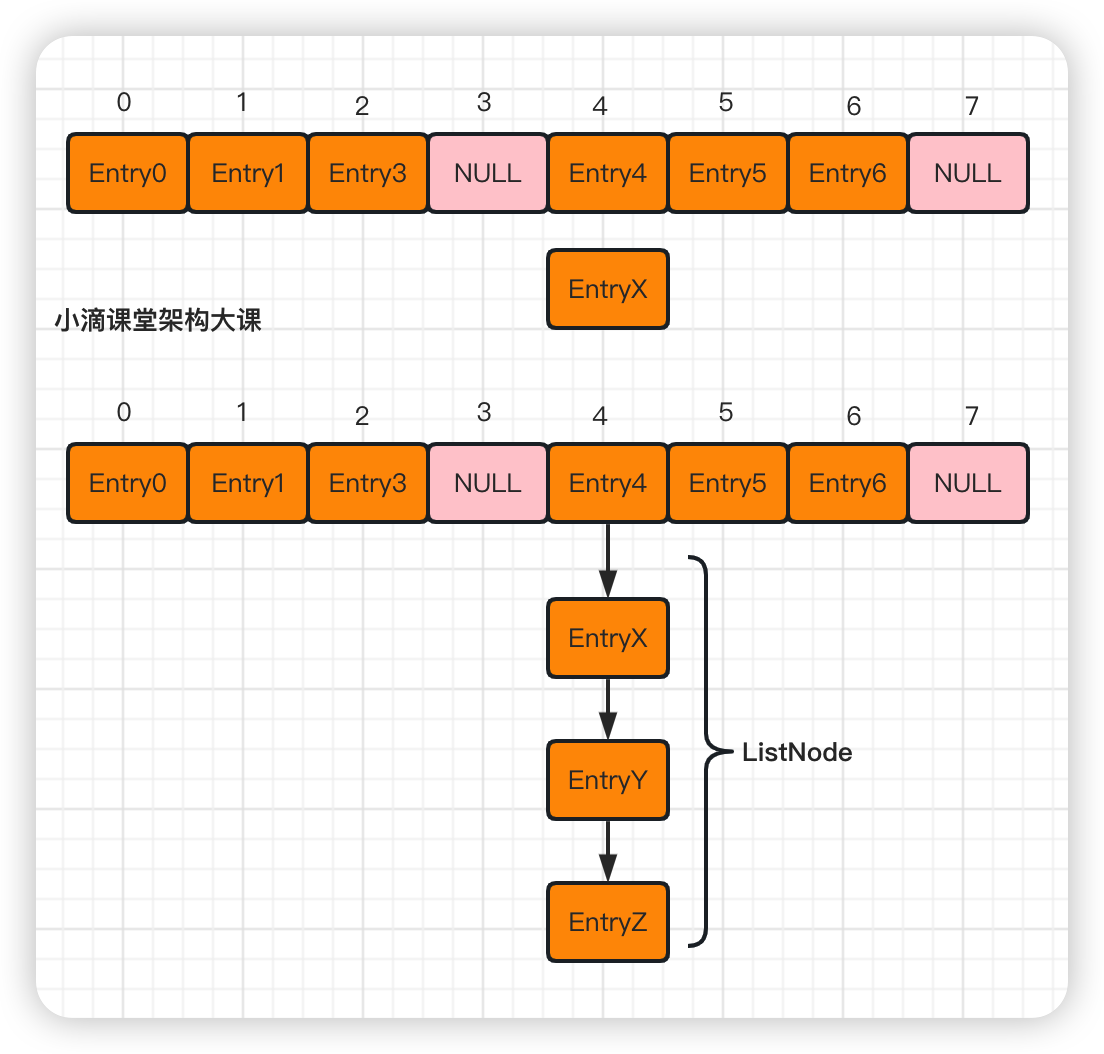
链表法
-
存操作
- 当发生冲突时,将冲突的元素放在散列表中的桶里,每个桶里存放一个链表 ListNode,
- 将冲突的元素放到链表中,每个元素都存储在链表的一个节点中
-
读操作
- 把 Key 通过哈希函数转化成数组下标, 即 bucket 桶的位置
- 找到 bucket 下标所对应的链表 ListNode,判断链表的第一个 Entry 的 key 是否正确,正确则直接获取对应的 value
- 如果不正确,说明产生 hash 冲突, 则顺着节点遍历该单链表,直到找到 key 一样的 entry,即可取值
-
注意
-
再哈希法
- 当发生冲突时,使用另一个不同的哈希函数,将冲突的元素重新哈希,以解决冲突问题
-
建立公共溢出区
- 当发生冲突时,将冲突的元素放到一个公共的溢出区中,公共溢出区中的元素,使用链表组织起来。
第 2 集 海量数据去重-BitMap 位图解决方案
简介: 海量数据去重-BitMap 位图解决方案
第 3 集 阿里面试题-编码实现 1 亿个数据找不存在的随机数
简介: 阿里面试题-编码实现 1 亿个数据找不存在的随机数
-
题目需求
- 有 1 千万个随机数,随机数的范围在 1 到 1 亿之间,将 1 到 1 亿之间没有在随机数中的数求出来
- 前提条件:使用 java 现有数据结构或自定义数据结构,要求高效和省空间
-
位图在 java 里面的实现 BitSet 类
-
是一个实现按需增长的位向量,位 Set 的每一个位置都有一个 boolean 值,默认初始值都是 false
-
底层实现是使用 long 数组作为内部存储结构的,所以 BitSet 的大小为 long 类型大小(64 位)的整数倍
-
如果指定了 bitset 的初始化大小,会规整到一个大于或者等于这个数字的 64 的整倍数(内存对齐)
- 比如 64 位,bitset 的大小是 1 个 long,而 65 位时,bitset 大小是 2 个 long,即 128 位
-
主要 API
void and(BitSet set) 对此目标位 set 和参数位 set 执行逻辑与操作。
void or(BitSet set) 对此目标位集执行逻辑或操作
void clear() 将此 BitSet 中的所有位设置为 false
void clear(int bitIndex):将指定索引处的位设置为 false
void set(int index) 将指定索引处的位设置为 true
boolean get(int index) 返回指定索引处的位值
int size():返回此 BitSet 中的位数(按逻辑大小)【表示位值时实际使用空间的位数,值是64的整数倍】
int length() 返回此 BitSet 的"逻辑大小",BitSet 中最高设置位的索引加 1
int cardinality() 返回此 BitSet 中设置为 true 的位数
-
API 测试
public static void testBitSet(){
BitSet bitSet = new BitSet();
bitSet.set(0);
bitSet.set(66);
System.out.println(bitSet.size()); // 128
System.out.println(bitSet.length()); // 67
System.out.println(bitSet.cardinality()); // 2
System.out.println("=====");
System.out.println(bitSet.get(0)); // true
System.out.println(bitSet.get(1)); // false
}
-
解答思路
-
海量数据 里面查找是否存在,排序,交集,并集等,这类题目基本就是使用位图解决
-
这类题目一般有两个面试形式
- 方式一 口述问答形式
- 给定 X 亿个不重复的 int 的整数,再给一个数,如何快速判断这个数是否在那 X 亿个数当中
- 解法:遍历 X 亿个数字,映射到 BitMap 中,对于给出的数,直接判断指定的位上存在不存在即可

public static void testBitMap2(){
//范围
int range = 100;
//个数
int totalNum = 10;
List<Integer> list=new ArrayList<>();
//1.声明一个BitSet
BitSet bitSet = new BitSet(range);
//2.生成1千万个随机数
for (int i = 0; i < totalNum; i++) {
int random = (int) (Math.random() * range);
bitSet.set(random);
list.add(random);
}
System.out.println("产生的随机数:"+list);
System.out.println("bitmap是1的个数(存在重复随机送):"+bitSet.cardinality());
System.out.println("bitmap是size:"+bitSet.size());
System.out.println("bitmap是length(bitmap里面占据的位数是1的位数+1):"+bitSet.length());
//3.遍历BitSet,将没有出现的数打印出来
for (int i = 0; i < range; i++) {
if (!bitSet.get(i)) {
System.out.print(i+",");
}
}
}
第 4 集 限定优惠劵业务解决方案-Redis7 的 BitMap 应用
简介: 限定优惠劵业务解决方案-Redis 的 BitMap 应用
第 5 集 海量数据处理-进阶版哈希表 BloomFilter
简介: 海量数据处理-进阶版哈希表 BloomFilter
-
背景需求
-
海量数据去重需求解决方案
- 如果用户的 ID 的数值类型是 32 位的话,如果有最大值是 2^32,需要用 512MB 空间的【位图来表示】
- 2^32bit=4294967296 比特(bit)=512 MB
- 如果用户的 ID 的数值类型是 64 位的话,如果有最大值是 2^64,需要用 2048PB 的位图来表示,硬件支撑不了
- 2^64bit=2^61 Byte= 2048 PB
- 所以 Bitmap 位图出现的问题
- 好处:空间复杂度不随原始集合内元素的个数增加而增加
- 坏处:空间复杂度随集合内【最大元素】增大而线性增大
-
海量数据下去重,如果是非数值类型的话如何判断
-
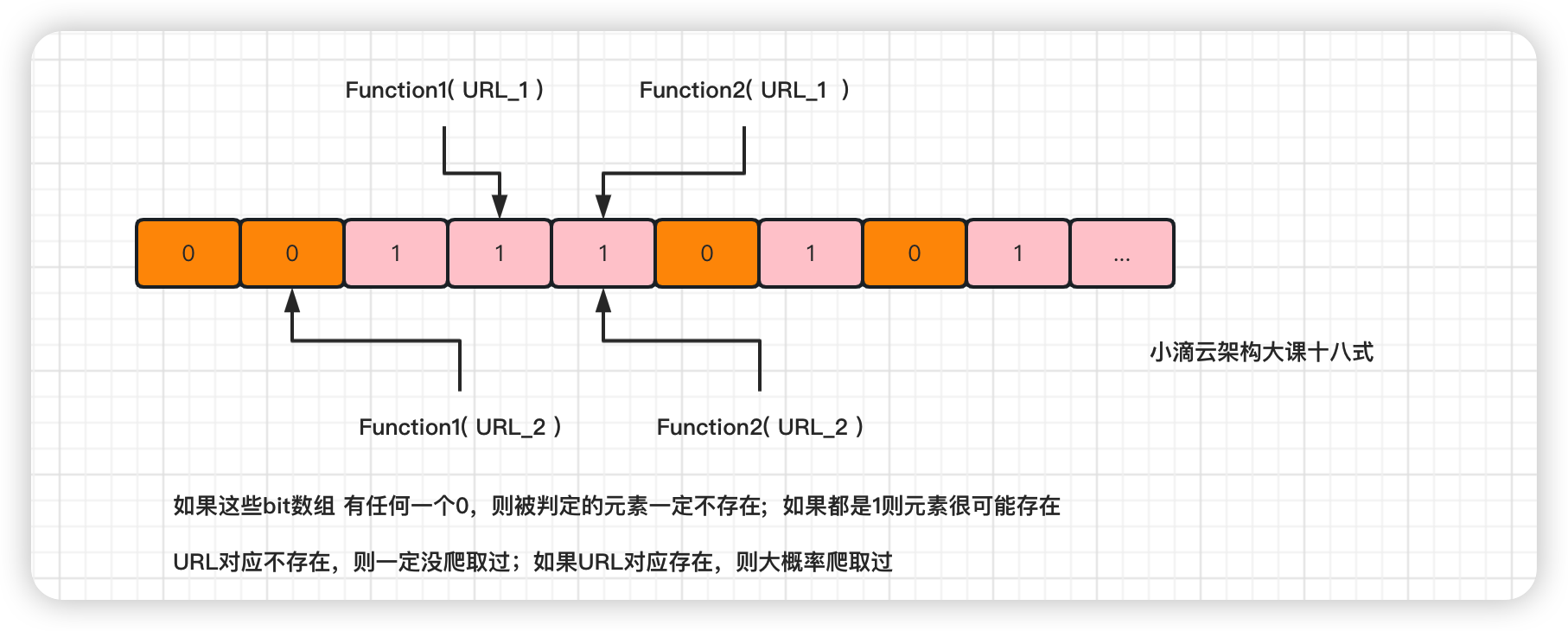
什么是布隆过滤器
-
1970 年由布隆提出的一种空间效率很高的概率型数据结构,它可以用于检索一个元素是否在一个集合中
-
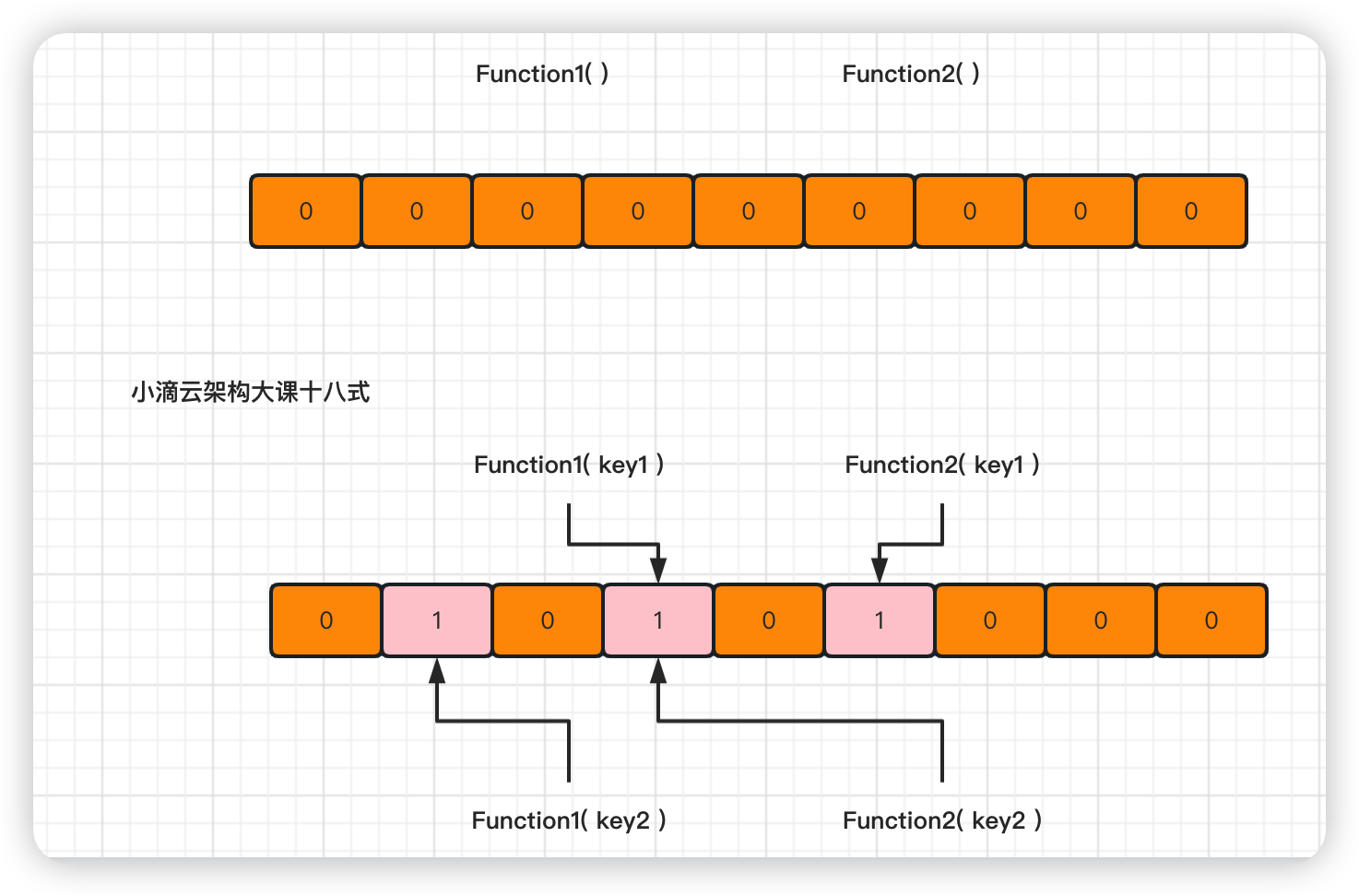
由只存 0 或 1 的位数组和多个 hash 算法, 进行判断数据 【一定不存在或者可能存在的算法】
-
如果这些 bit 数组 有任何一个 0,则被判定的元素一定不在; 如果都是 1 则被检元素很可能在
-
对比 bitmap 位图,布隆过滤器适合更多类型元素,通过 hash 值转换
-
原理
-
将元素添加到一个 bitmap 数组中,每个散列函数将元素映射到 bitmap 数组中的一个位置
-
如果该位置已经被占用,则将该位置置为 1,否则置为 0
-
当要查询一个元素是否存在时,只需要计算该元素的散列值,并检查 bitmap 数组中对应的位置是否已经被置为 1
-
如果都是 1,则该元素可能存在,否则肯定不存在。
-
优点
- 占用空间小,查询速度快,空间效率和查询时间都远远超过一般的算法
-
缺点
- 有一定的误识别率,有一定的误识别率,即某个元素可能存在,但实际上并不存在。
- 删除困难,因为无法确定某个位置是由哪个元素映射而来的
-
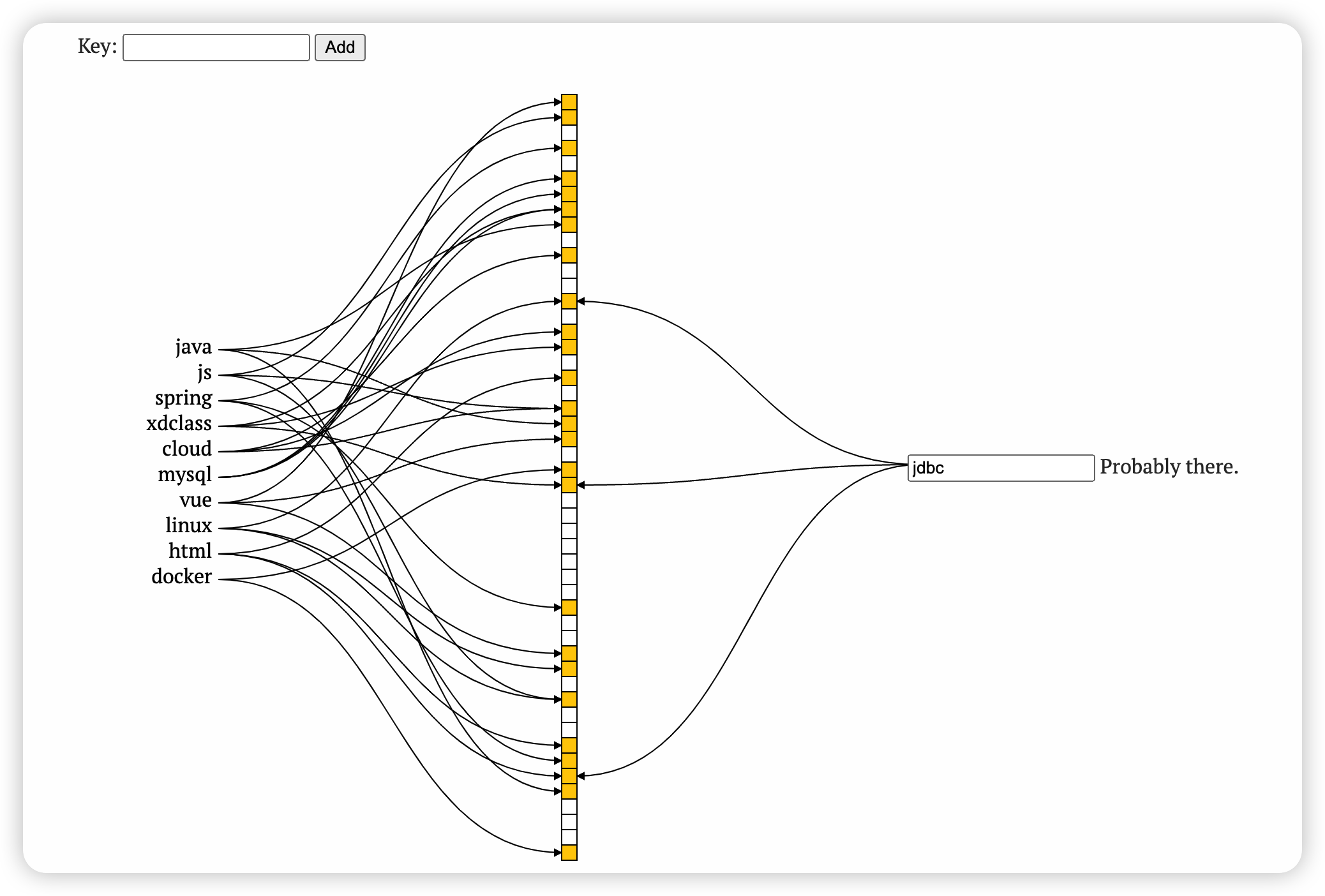
案例效果测试
-
记住结论:不存在的一定不存在,存在的不一定存在
-
注意点
- 布隆过滤器存在误判率,数组越小,所占的空间越小,误判率越高;如果要降低误判率,则数组越长,但所占空间越大
- 最大限度的避免误差, 选取的位数组应尽量大, hash 函数的个数尽量多, 但空间占用的浪费和性能的下降
- 业务选择的时候, 需要误判率与 bit 数组长度和 hash 函数数量的平衡
- 布隆过滤器不能直接删除元素,因为所属的 bit 可能多个元素有使用
- 如果要删除则需要重新生成布隆过滤器,或者把布隆过滤器改造成带引用计数的方式
第 6 集 BloomFilter 应用-垃圾邮件和缓存穿透解决方案
简介: BloomFilter 应用-垃圾邮件和缓存穿透解决方案
- 布隆过滤器
- 由只存 0 或 1 的位数组和多个 hash 算法, 进行判断数据 【一定不存在或者可能存在的算法】
-
应用场景:解决海量数据下非精确过滤的业务场景
- 垃圾邮件解决方案(垃圾短信、黑名单同理)
- 收集一组具有特定特征的垃圾邮件样本,这些样本可以是文本内容或其他特征,比如发件人、收件人等
- 将这些样本的特征信息进行哈希处理,并将处理后的结果存储在布隆过滤器中。
- 接下来,当有新的电子邮件到达时,将该邮件的特征信息也进行哈希处理,并且与布隆过滤器中的信息进行比较
- 如果布隆过滤器中存在该邮件的特征信息,则判断该邮件为垃圾邮件;如果不存在,则判断该邮件为正常邮件

-
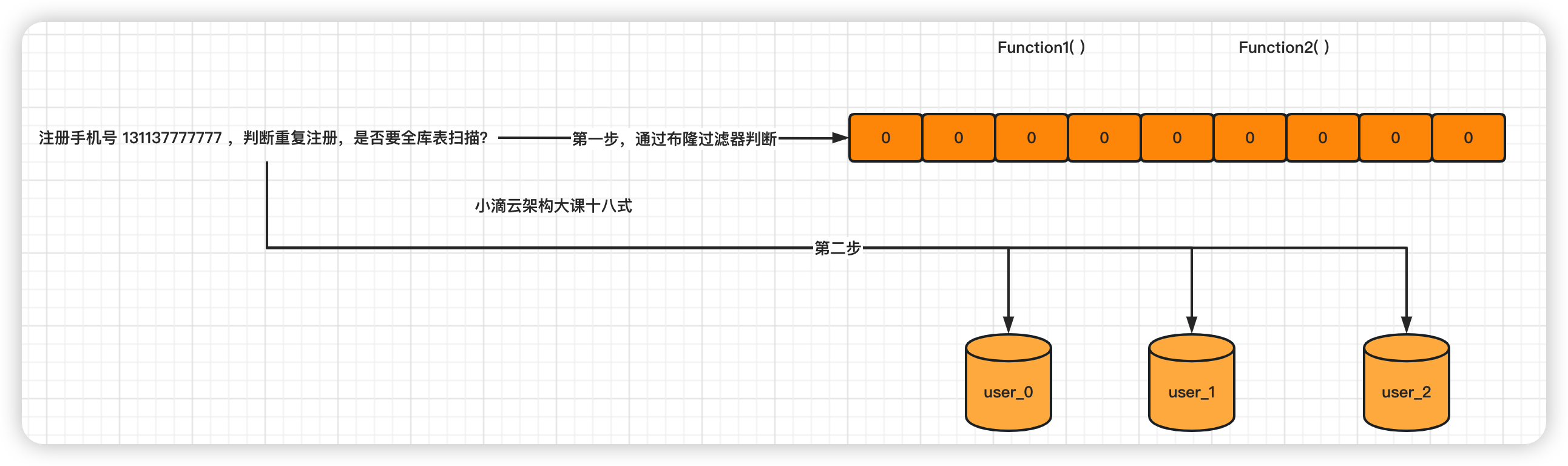
解决缓存穿透解决方案
- 什么是缓存穿透(查询不存在数据)
- 查询一个不存在的数据,由于缓存是不命中的,如发起为 id 为“-1”不存在的数据
- 如果从存储层查不到数据则不写入缓存,导致这个不存在的数据每次请求都要到存储层去查询,
- 大量查询不存在的数据,可能 DB 就挂掉了,是黑客利用不存在的 key 频繁攻击应用的一种方式
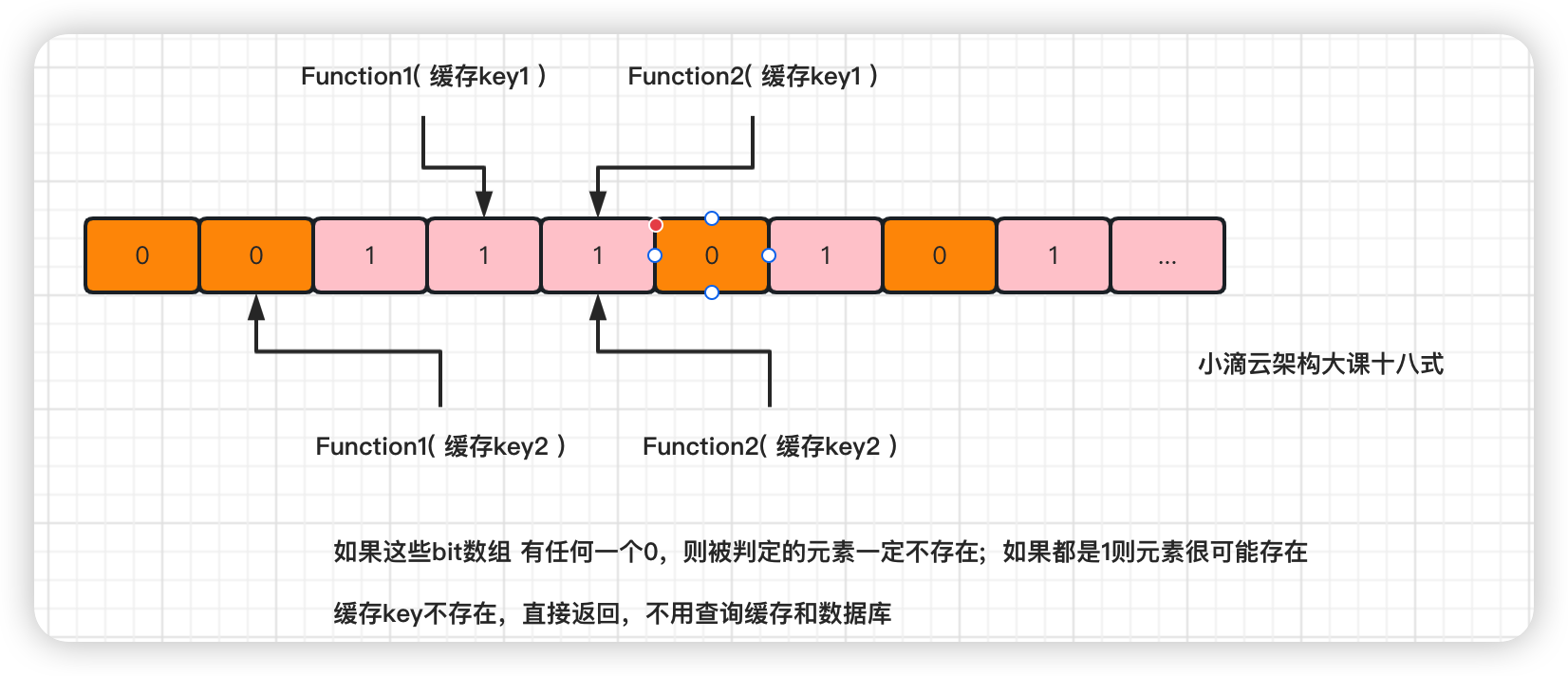
- 将所有要【缓存的数据】经过处理后存储布隆过滤器中,即对应的 bit 上是 1
- 当外部请求发起时,首先会把请求的参数 通过哈希算法处理,获得相应的哈希值;
- 根据哈希值计算出位数组中的位置,如果全部计算的 hash 值对于的 bit 存储都是 1
- 则表示数据在合理中,从缓存读出(缓存失效则从数据库中取出)
- 如果计算的 hash 值对于的 bit 存储存在一个是 0 或以上,则表示这条数据不合理,直接返回数据不存在,不查缓存和数据库
- 如果布隆过滤器认为值不存在,那么值一定是不存在的,无需查询缓存也无需查询数据库
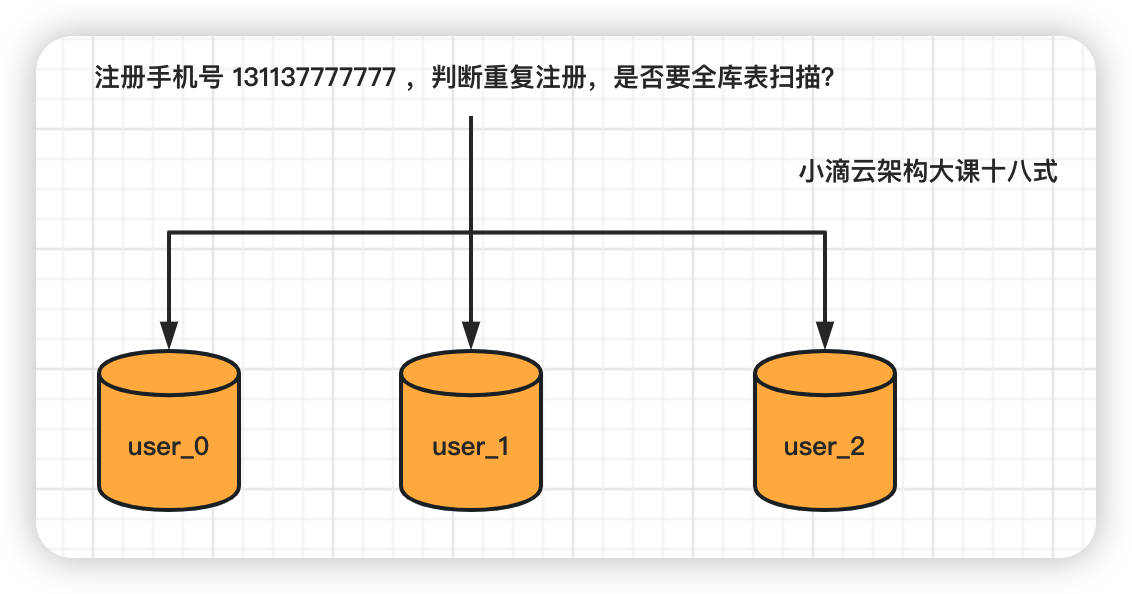
第 7 集 爬虫 URL 去重和分库分表注册手机号唯一性解决方案
简介: 爬虫 URL 去重和分库分表注册手机号唯一性解决方案
第 8 集 爬虫 URL 去重实战-SpringBoot3.0+Guava 布隆过滤器《上》
简介:爬虫 URL 去重实战-SpringBoot3.0+Guava 布隆过滤器《上》
-
前置环境准备
- 本地 JDK17 安装(SpringBoot3.0 要求 JDK17)
-
项目开发
-
依赖包引入
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.12.0</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.1-jre</version>
</dependency>
</dependencies>
-
数据准备 (随机生成 500 万 URL)
@Test
public void testGeneUrl() {
try{
File file = new File("/Users/xdclass/Desktop/dat.txt");
if (!file.exists()) {
file.createNewFile(); // 创建新文件,有同名的文件的话直接覆盖
}
FileOutputStream fos = new FileOutputStream(file, true);
OutputStreamWriter osw = new OutputStreamWriter(fos);
BufferedWriter bw = new BufferedWriter(osw);
StringBuilder builder = new StringBuilder();
for (int i = 0; i < 5000000; i++) {
String name = RandomStringUtils.randomAlphabetic(5);
String fileName = "https://www." + name + ".com" + i + "\n";
builder.append(fileName);
}
bw.write(String.valueOf(builder));
bw.newLine();
bw.flush();
bw.close();
osw.close();
fos.close();
} catch (FileNotFoundException e1) {
e1.printStackTrace();
} catch (IOException e2) {
e2.printStackTrace();
}
}
-
Guava 包布隆过滤器介绍
//参数一: 指定布隆过滤器中存的是什么类型的数据,有 IntegerFunnel,LongFunnel,StringCharsetFunnel
//参数二: 预期需要存储的数据量
//参数三: 误判率,默认是 0.03
BloomFilter.create(Funnels.stringFunnel(Charset.forName("UTF-8")), 5000000, 0.01);
第 9 集 爬虫 URL 去重实战-SpringBoot3.0+Guava 布隆过滤器《下》
简介:爬虫 URL 去重实战-SpringBoot3.0+Guava 布隆过滤器《下》
@Bean
public Set set() throws IOException {
Set<String> set = new LinkedHashSet<>();
FileInputStream inputStream = new FileInputStream(new File("/Users/xdclass/Desktop/dat.txt"));
InputStreamReader streamReader = new InputStreamReader(inputStream);
BufferedReader reader = new BufferedReader(streamReader);
String line = null;
while (true) {
line = reader.readLine();
if (line != null) {
set.add(line);
} else {
break;
}
}
inputStream.close();
return set;
}
@Bean
public BloomFilter bloomFilter() throws IOException {
BloomFilter bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("UTF-8")), 5000000, 0.01);
FileInputStream inputStream = new FileInputStream(new File("/Users/xdclass/Desktop/dat.txt"));
InputStreamReader streamReader = new InputStreamReader(inputStream);
BufferedReader reader = new BufferedReader(streamReader);
String line = null;
while (true) {
line = reader.readLine();
if (line != null) {
bloomFilter.put(line);
} else {
break;
}
}
inputStream.close();
return bloomFilter;
}
@RestController
@RequestMapping("/api")
public class FilterController {
@Autowired
private BloomFilter<String> bloomFilter;
@Autowired
private Set set;
@GetMapping("/bloom")
public String list() throws IOException {
//判断是否包含这个内容
if (bloomFilter.mightContain("https://www.dhVrX.com5")) {
return "命中了";
} else {
return "没命中";
}
}
@GetMapping("/set")
public String set() {
if (set.contains("httssps://www.shncb.com999663")) {
return "命中了";
} else {
return "没命中";
}
}
}
第 10 集 哈希表-位图和布隆过滤器特点和业务选择说明
简介:哈希表-位图和布隆过滤器特点和业务选择说明
-
案例说明
- 情况一
- 小滴课堂官网,用户总量 1 亿,日活 5 千万,用户 id 是 64 位长整整型,需要统计每天登录的用户数
- 采用普通的集合存储用户 id,空间大小 64 * 5 千万= 381 MB(存储 5 千万个 64 位的 id)
- 采用 BitMap 位图存储用户 id,空间大小 1 * 10^8 = 11.9MB(构建的数组长度需要支持 1 亿个 bit)
- 结论:位图 优于 普通集合
- 情况二
- 小滴课堂官网,用户总量 1 亿,日活 10 千万,用户 id 是 64 位长整整型,需要统计每天登录的用户数
- 采用普通的集合存储用户 id,空间大小 64 *10 万= 0.76 MB(存储 10 万个 64 位的 id)
- 采用 BitMap 位图存储用户 id,空间大小 1 *10^8 = 11.9MB(构建的数组长度需要支持 1 亿个 bit)
- 结论:普通集合 优于 位图 ,业务的总数据范围(总用户数)与实际存储大小(日活用户数)影响
-
哈希表、位图和布隆过滤器对比
-
共同点
- 本质都是一个数组,都是基于哈希表的基础延伸出来,存在交集,边界模糊
- 布隆过滤器本身就是基于位图的,是对位图的一种改进
-
差异
- 位图一个位置只有一个元素使用,布隆过滤器一个位置可能多个元素都会使用
- 位图使用一个函数, 布隆过滤器使用多个 hash 函数
- 位图是精准匹配,用整型值通过直接寻址的方式进行映射; 而布隆过滤器是概率性匹配
- 位图会节省 hash 函数的耗时,而空间是否节省,看业务场景而定;
- 布隆过滤器的 hash 函数会耗时,海量数据下会比位图更省空间;
- bitmap 存储一个元素需一个 bit, 布隆过滤器存储一个元素小于一个 bit
- bitmap 只用一个位置用来判断状态 ,bloomfilter 用多个位置用来判断状态
-
变种
- 如果布隆过滤器哈希函数个数是 1 个,函数里面就是位图寻址;然后哈希表不存储实际的值,存储一个 bit 表示元素是否存在
- 那这个数据结构应该是叫 哈希表 还是 位图,还是布隆过滤器?